深入剖析分布式监控 CAT —— 消息文件存储
项目简介
CAT(Central Application Tracking),是基于 Java 开发的分布式实时监控系统。CAT 目前在美团点评的产品定位是应用层的统一监控组件,在中间件(RPC、数据库、缓存、MQ 等)框架中得到广泛应用,为各业务线提供系统的性能指标、健康状况、实时告警等。
CAT 目前在美团点评已经基本覆盖全部业务线,每天处理的消息总量 3200 亿+,存储消息量近 400TB,在通信、计算、存储方面都遇到了很大的挑战。
感兴趣的朋友欢迎 Star 开源项目 https://github.com/dianping/cat。
消息模型
组织关系
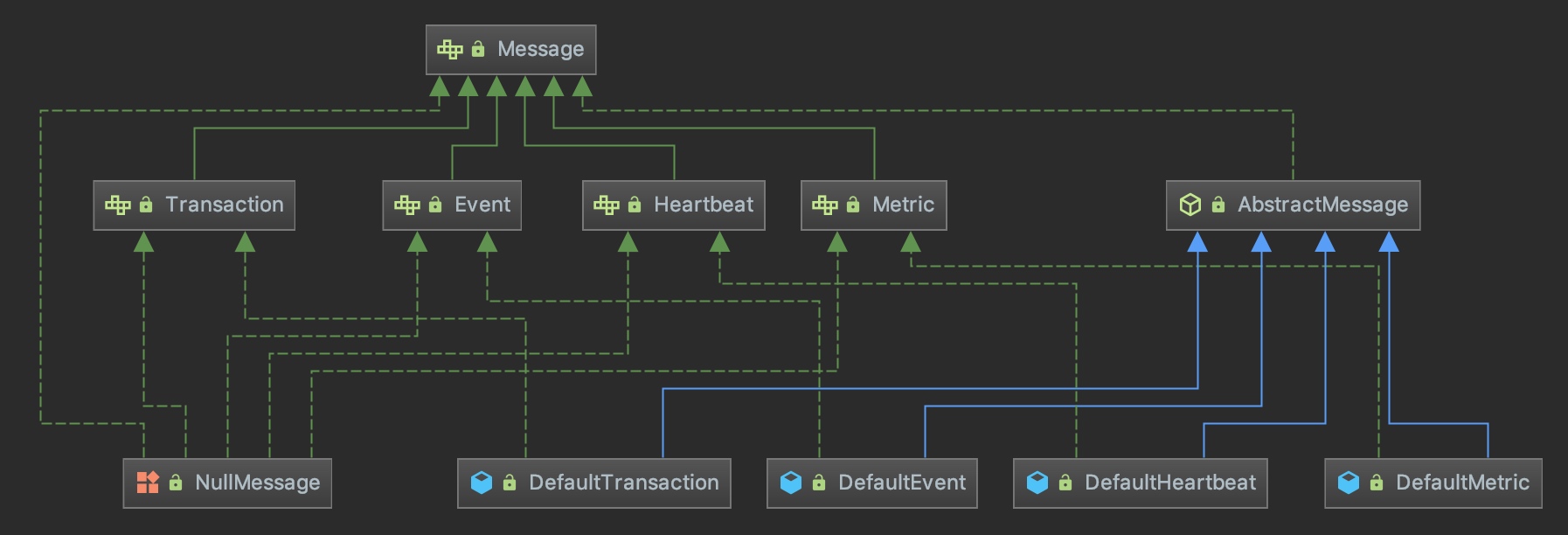
消息类型
| 消息类型 | 职责 | 适用场景 |
|---|---|---|
| Transaction | 记录一段代码的执行时间和次数 | 1. 执行时间较长的业务逻辑监控。 2. 记录完整调用过程。 |
| Event | 记录一段代码的执行次数或事件是否发生 | 统计计数或异常事件记录 |
| Metric | 记录一个业务指标的变化趋势 | 业务指标的发生次数、平均值、总和,例如商品订单。 |
| Heartbeat | 定期上报数据或执行某些任务 | 定期上报统计信息,如 CPU 利用率、内存利用率、连接池状态等。 |
埋点示例
public void shopInfo() {
Transaction t1 = Cat.newTransaction("URL", "/api/v1/shop");
try {
Transaction t2 = Cat.newTransaction("Redis", "getShop");
String result = getCache();
t2.complete();
if (result != null) {
Cat.logEvent("CacheHit", "Success");
} else {
Cat.logEvent("CacheHit", "Fail");
}
Transaction t3 = Cat.newTransaction("Rpc", "Call");
try {
doRpcCall();
} catch (Exception e) {
t3.setStatus(e);
Cat.logError(e);
} finally {
t3.complete();
}
} catch (Exception e) {
t1.setStatus(e);
Cat.logError(e);
} finally {
t1.complete();
}
}
private String getCache() throws InterruptedException {
Thread.sleep(10); // mock cache duration
return null;
}
private void doRpcCall() {
throw new RuntimeException("rpc call timeout"); // mock rpc timeout
}
LogView 消息树
LogView 不仅可以分析核心流程的性能耗时,而且可以帮助用户快速排查和定位问题。例如上述埋点示例对应的 LogView:
- Transation 消息是可嵌套的。
- logError 可记录异常堆栈,是一种特殊的 Event 消息。

分布式调用链路
CAT 可以提供简单的分布式链路功能,典型的场景就是 RPC 调用。例如客户端 A 调用服务端 B,客户端 A 会生成 2 个 MessageID:表示客户端 A 调用过程的 MessageID-1 和表示服务端 B 执行过程的 MessageID-2,MessageID-2 在客户端 A 发起调用的时候传递给服务端 B,MessageID-2 是 MessageID-1 的儿子节点。
消息流水线
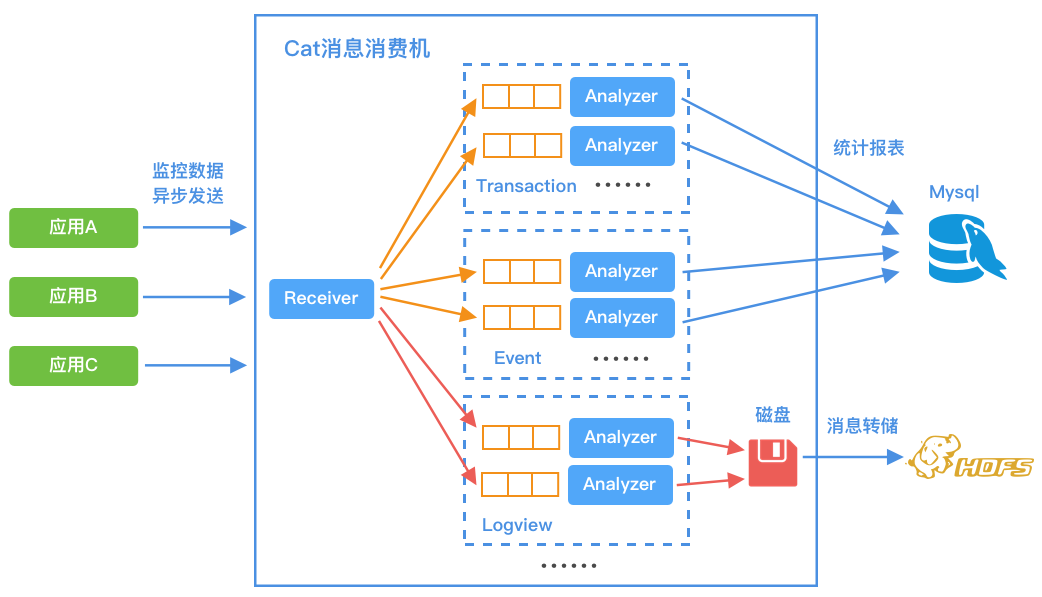
如上图所示,实时报表分析是整个监控系统的核心,CAT 服务端接收客户端上报的原始数据,分发到不同类型的 Analyzer 线程中,每种类型的任务由一组 Analyzer 线程构成。由于原始消息的数量庞大,所以需要对数据进行加工、统计后生成丰富的报表,满足业务方排查问题以及性能分析的需求。
其中 Logview 的 Analyzer 线程是本文讨论的重点,它会收集全量的原始消息,并实时写入磁盘,类似实现一个高吞吐量的简易版消息系统。此外需要具备一定限度的随机读能力,方便业务方定位问题发生时的“案发现场”。
对于历史的 Logview 文件会异步上传至 HDFS。
消息文件存储
CAT 针对消息写多读少的场景,设计并实现了一套文件存储。以小时为单位进行集中式存储,每个小时对应一个存储目录,存储文件分为索引文件和数据文件。用户可以根据 MessageID 快读定位到某一个消息。
消息 ID 设计
CAT 客户端会为每个消息树都会分配唯一的 MessageID,MessageID 总共分为四段,示例格式:shop.service-0a010101-431699-1000。
- 第一段是应用名shop.service。
- 第二段是客户端机器 IP 的16进制码,0a010101 表示10.1.1.1。
- 第三段是系统当前时间除以小时得到的整点数,431699 代表 2019-04-01 19:00:00。
- 第四段是客户端机器当前小时消息的连续递增号。(
存储设计的重要依据点)
文件存储 V1.0
总体概貌
V1.0 版本的文件存储设计比较简单粗暴,每个客户端 IP 节点对应分别对应一个索引文件和数据文件。

单个 IP 视角

- 每个索引内容由存储块首地址和块内偏移地址组成,共 6byte。
- 每个索引内容的序号与消息序列号一一对应,因为消息序列号是连续递增号,所以索引文件基本可以保证是顺序写。
- 为了减少磁盘IO交互和写入时间,消息采用批量 Gzip 压缩后顺序 append 至数据文件。
优缺点分析
| 优点 | 缺点 |
|---|---|
| 1. 简单易懂,实现复杂度不高。 2. 根据消息序列号可快速定位索引。 |
1. 随着业务规模不断扩展,存储文件的数量并不可控。 2. 数据文件节点过多导致随机 IO 恶化,机器 Load 飙高。 |
文件存储 V2.0
V2.0 文件存储进行了重新设计,以解决 V2.0 数据文件节点过多以及随机 IO 恶化的问题。
总体概貌
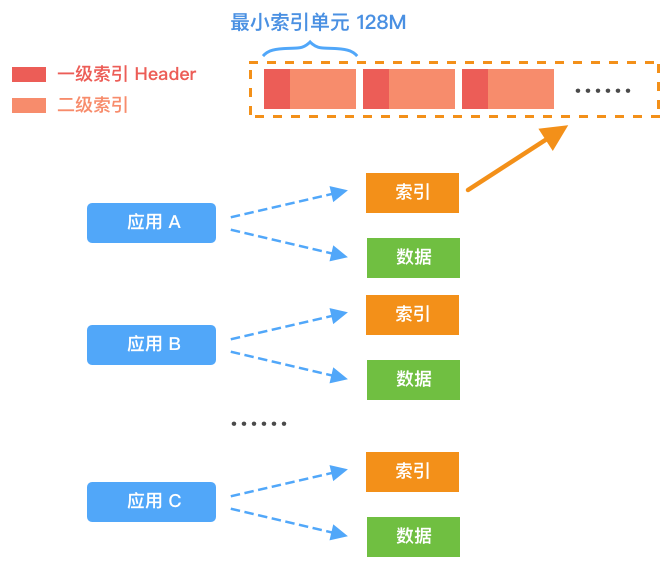
V2.0 核心设计思想:
- 合并同一个应用的所有 IP 节点。
- 引入多级索引,建立 IP、Index、DataOffset 的映射关系。
- 同一个 IP 的索引数据尽可能保证顺序存储。
单个索引文件视角
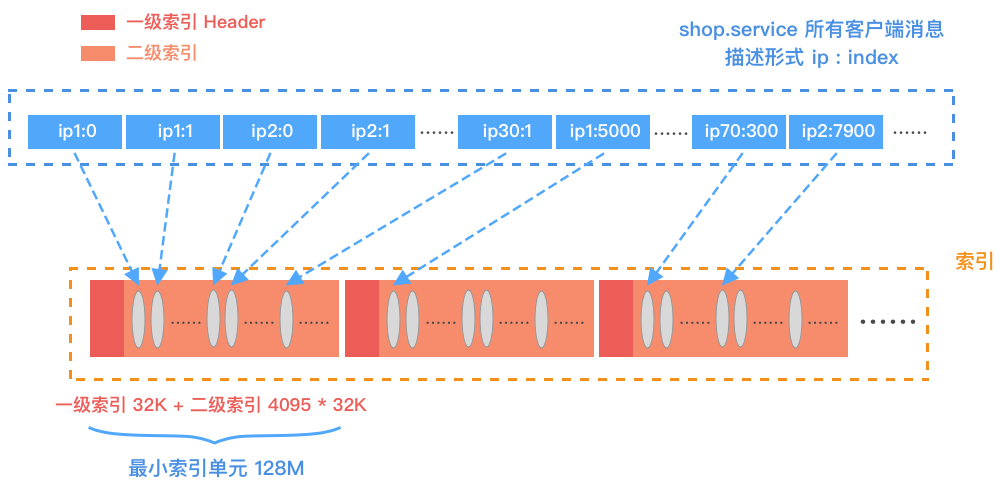
索引文件存储的特点:
- 需要根据 IP + Index 建立一级索引。
- 不同 IP 节点跳跃式存储,每次划分一段连续且固定大小的存储空间。
- 同一个 IP 节点根据 Index 在每块固定大小的存储空间内顺序存储。
最小索引单元视角
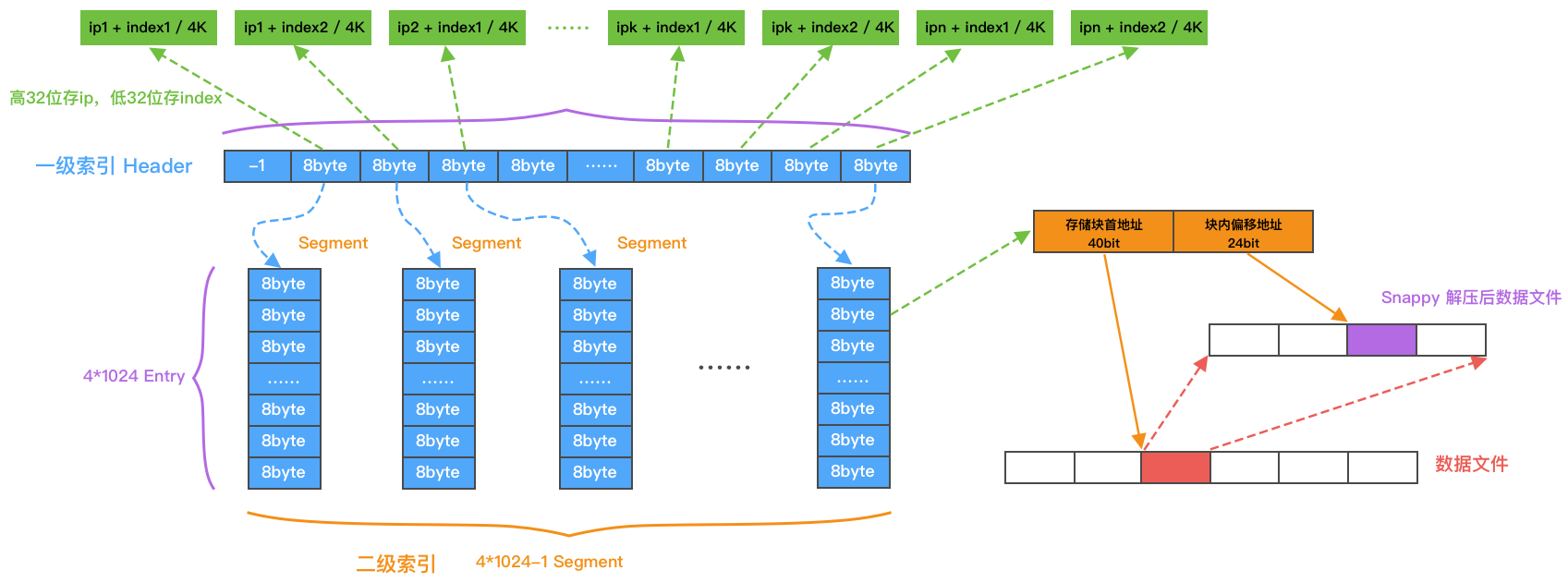
上图是索引结构的最小单元,每个索引文件由若干个最小单元组成。每个单元分为 4 * 1024 个 Segment,第一个 Segment 作为我们的一级索引 Header,存储 IP、消息序列号与 Segment 的映射信息。剩余 4 * 1024 - 1 个 Segment 作为二级索引,存储消息的地址。一级索引和二级索引都采用 8byte 存储每个索引数据。
一级索引 Header
- 一级索引共由 4096 个 8byte 构成。
-
每个索引数据由 64 位存储,前 32 位为 IP,后 32 位为 baseIndex。
baseIndex = index / 4096,index 为消息递增序列号。
二级索引
- 二级索引共由 4095 个 segment 构成,每个 segment 由 4096 个 8byte 构成。
- 每个索引数据由 64 位存储,前 40 位为存储块的首地址,后 24 位为解压后的块内偏移地址。
一级索引 Header 与二级索引关系
- 一级索引第一个 8byte 存储可存储魔数(图中用 -1 表示),用于标识文件有效性。
- 一级索引剩余 4095 个 8byte 分别与二级索引中每个 segment 顺序一一对应。
如何定位一个消息
- 根据应用名定位对应的索引文件和数据文件。
-
加载索引文件中的所有一级索引,建立 IP、baseIndex、segmentIndex 的映射表。
从整个索引文件角度看,segmentIndex 是递增的,1 ~ 4095、4097 ~ 8291,以此类推。
- 根据消息序列号 index 计算得出 baseIndex。
- 通过 IP、baseIndex 查找映射表,定位 segmentIndex。
- 计算消息所对应segment的偏移地址:segmentOffset = (index % 4096) * 8,获得索引数据。
- 根据索引数据中块偏移地址读取压缩的数据块,Snappy 解压后根据块内偏移地址读取消息的二进制数据。
总结
针对类似消息系统的数据存储,索引设计是比较重要的一环,方案并不是唯一的,需要不断推敲和完善。文件存储常用的一些性能优化手段:
- 批量、顺序写,减少磁盘交互次数。
- 4K 对齐写入。
- 数据压缩,常用的压缩算法有 Gzip、Snappy、LZ4。
- 对象池,避免内存频繁分配。
实践出真知,推荐大家学习下 Kafka 以及 RocketMQ 源码,例如 RocketMQ 中单个文件混合存储的方式、类似 HashMap 结构的 Index 文件设计以及内存映射等都是比较好的学习资源。

